Performance optimisation
If you're self-hosting Open Topo Data and want better throughput or to run on a cheaper instance there's a few things you can do.
Server hardware
Open Topo Data is mostly CPU bound. It benefits from fast CPUs and high virtual core count.
A spinning hard drive is enough to saturate the CPU so an SSD is not needed. Using a network filestore or keeping tiles in cloud storage will probably introduce enough latency to become the bottleneck.
It uses very little memory.
Queries
Batch request are faster (per point queried) than single-point requests, and large batches are faster than small ones. Increase max_locations_per_request to as much as you can fit in a a URL.
Batch queries are fastest if the points are located next to each other. Sorting the locations you are querying before batching will improve performance. Ideally sort by some block-level attribute like postal code or state/county/region, or by something like round(lat, 1), round(lon, 1) depending on your tile size.
If the requests are very large and the server has several CPU cores, try splitting the request and sending it simultaneously. The optimum for the number of requests is slightly higher than the amount of CPU cores used by Open Topo Data. The number of CPU cores used is displayed when OpenTopodata is started. If you missed the log message, you can find iw with the following command:
Dataset format
A request spends 90% of its time reading the dataset, so the format your raster tiles are in can greatly impact performance.
The most optimal way to store rasters depends heavily on the dataset, but here's some rules of thumb:
- Tile size Files around 2,000 to 20,000 are pixels square are good. Too small and you end up opening lots of files for batch requests; too large and read time is slower.
- Format Actually this one is clear: use GeoTIFFs. I haven't found anything faster (supported by GDAL) for any of the datasets in the public API.
- Compression GDAL options
-co PREDICTOR=1is often fastest to read, though can make files larger.-co COMPRESS=DEFLATEis often fastest to read, though can be larger thanlzwandzstdespecially for floating point data.-co ZLEVEL=1gives a small read performance boost, makes writing noticeably faster, while barely increasing size.- All of the above are minor differences compared to using uncompressed GeoTIFFs or other formats, don't stress it.
Open Topo Data doesn't support zstd (as it's not supported yet by rasterio and compiling GDAL from source greatly increases build times) but there's an old branch zstd that has support
Multiple datasets
Add tight wgs84_bounds for multiple datasets. If your dataset isn't a filled rectangle (e.g., you have one dataset covering CONUS, AK, and HI but not Canada) you might want to split it into multiple datasets with tight bounds.
Version
Open Topo Data gets faster each release, either though performance improvements or from updated dependencies.
Use the latest version.
This is especially true if you're using a version older than 1.5.0, as this release gives a 2x+ speedup.
Testing performance
You can easily test throughput using ab:
You should test on your particular dataset and batch size. It doesn't seem to matter much if you use a fixed url or build a list with different urls for each request: there's no response caching (though your OS may cache files and GDAL may cache raster blocks.)
Benchmark results
Here are some plots I made benchmarking version 1.5.0 with 8m NZ DEM. The specific results probably won't apply to your dataset, and I included the general takeaways above.
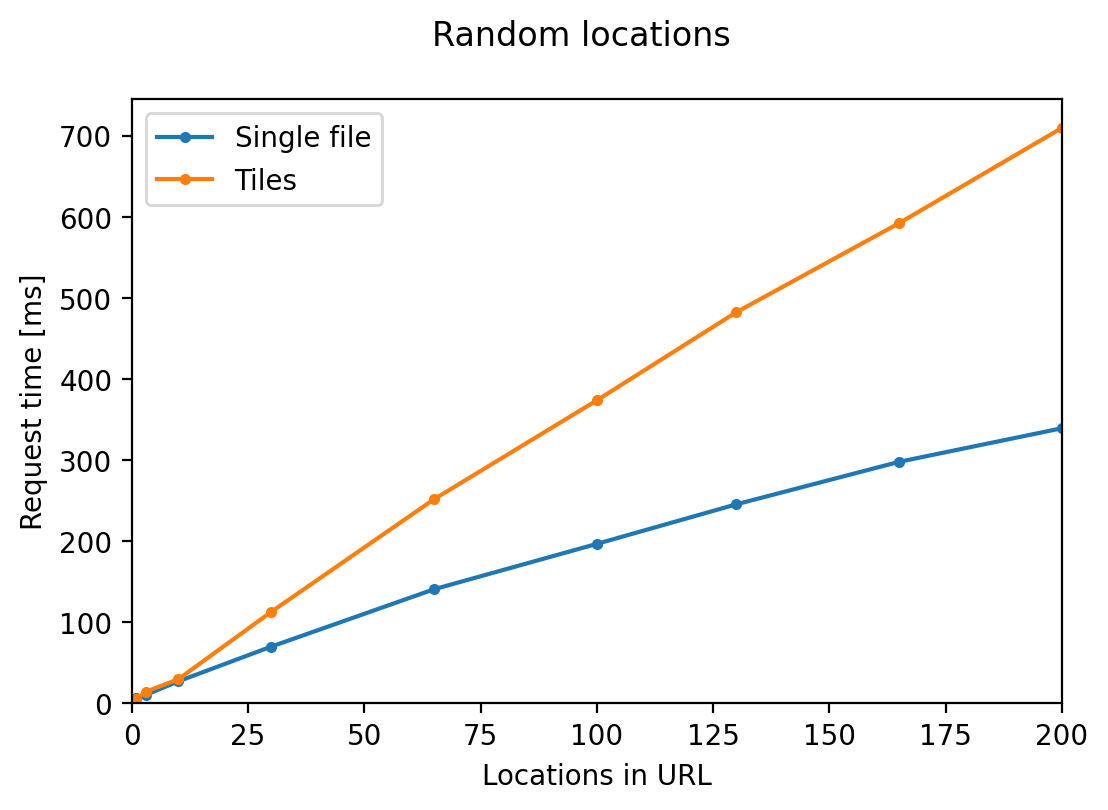
Response time grows sublinearly with batch size. Querying locations that lie on the same tile is 2x faster than locations over multiple tiles.
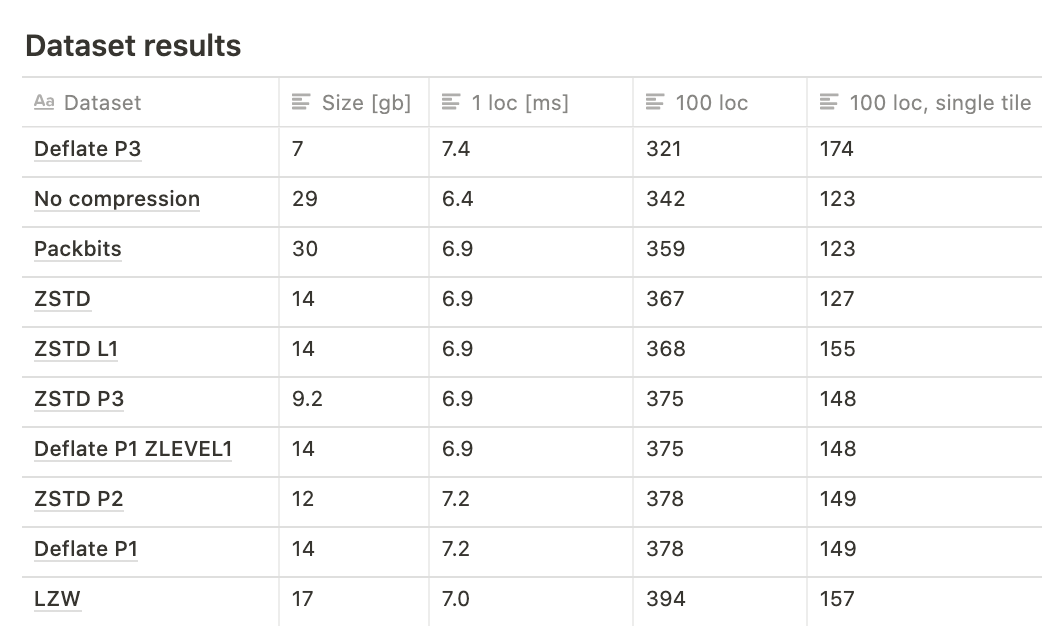
Read time and file size for different GeoTIFF compression methods.